Abstract
Videos take a lot of time to transport over the network, hence running analytics on the live video on embedded or mobile devices has become an important system driver. Considering that such devices, e.g., surveillance cameras or AR/VR gadgets, are resource constrained, creating lightweight deep neural networks (DNNs) for embedded devices is crucial. None of the current approximation techniques for object classification DNNs can adapt to changing runtime conditions, e.g., changes in resource availability on the device, the content characteristics, or requirements from the user. In this paper, we introduce ApproxNet, a video object classification system for embedded or mobile clients. It enables novel dynamic approximation techniques to achieve desired inference latency and accuracy trade-off under changing runtime conditions. It achieves this by enabling two approximation knobs within a single DNN model, rather than creating and maintaining an ensemble of models (e.g., MCDNN [MobiSys-16]. We show that ApproxNet can adapt seamlessly at runtime to these changes, provides low and stable latency for the image and video frame classification problems, and show the improvement in accuracy and latency over ResNet [CVPR-16], MCDNN [MobiSys-16], MobileNets [Google-17], NestDNN [MobiCom-18], and MSDNet [ICLR-18].
Techniques
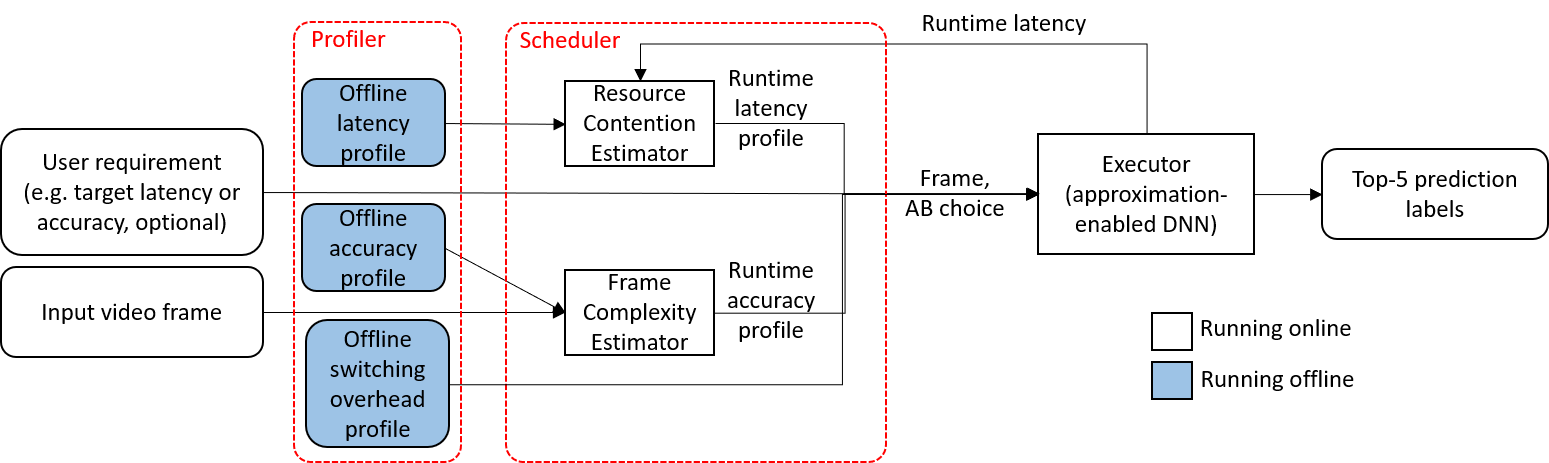
We show the overall structure with three major functional units: executor, profiler, and scheduler in figure above. ApproxNet takes a video frame and optional user requirement for target accuracy or latency as an input, and produces top-5 prediction labels of the object classes as outputs.
The executor is an approximation-enabled, single-model DNN. Specifically, the single-model design largely reduces the switching overhead so as to support the adaptive system. On the other hand, the multiple approximation branches (ABs), each with variable latency and accuracy specs, are the key to support dynamic content and contention conditions. ApproxNet is designed to provide real-time processing speed (30 fps) on our target device (NVIDIA Jetson TX2). Compared to the previous single-model designs like MSDNet and BranchyNet, ApproxNet provides novelty in enabling both depth and shape as the approximation knob for run-time calibration.
The scheduler is the key component to react to the dynamic content characteristics and resource contention. Specifically, it selects an AB to execute by combining the precise accuracy estimation of each AB due to changing content characteristics via a Frame Complexity Estimator (FCE), the precise latency estimation of each AB due to resource contention via a Resource Contention Estimator (RCE), and the switching overhead among ABs. It finally reaches a decision on which AB to use based on the user's latency or accuracy requirement and its internal accuracy, latency, and overhead estimation.
Finally, to achieve our goal of real-time processing, low switching overhead, and improved performance under dynamic conditions, we design an offline profiler. We collect three profiles offline – first, the accuracy profile for each AB on video frames of different complexity categories; second, the inference latency profile for each AB under variable resource contention, and third, the switching overhead between any two ABs.
Cite
If you find this work useful in your own research, please consider citing:
@article{xu2021approxnet,
title={{ApproxNet}: Content and Contention-Aware Video Object Classification System for Embedded Clients},
journal = {ACM Trans. Sen. Netw. (TOSN)},
author={Xu, Ran and Kumar, Rakesh and Wang, Pengcheng and Bai, Peter and Meghanath, Ganga and Chaterji, Somali and Mitra, Subrata and Bagchi, Saurabh},
year={2021},
volume={18},
number={1},
numpages={27},
publisher={ACM}
}
Funding Source
This work is supported in part by the Wabash Heartland Innovation Network (WHIN) award from Lilly Endowment, NSF grant CCF-1919197, and Army Research Lab Contract number W911NF-20-2-0026. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the sponsors.
For questions about paper, please contact Ran Xu at martin.xuran@gmail.com