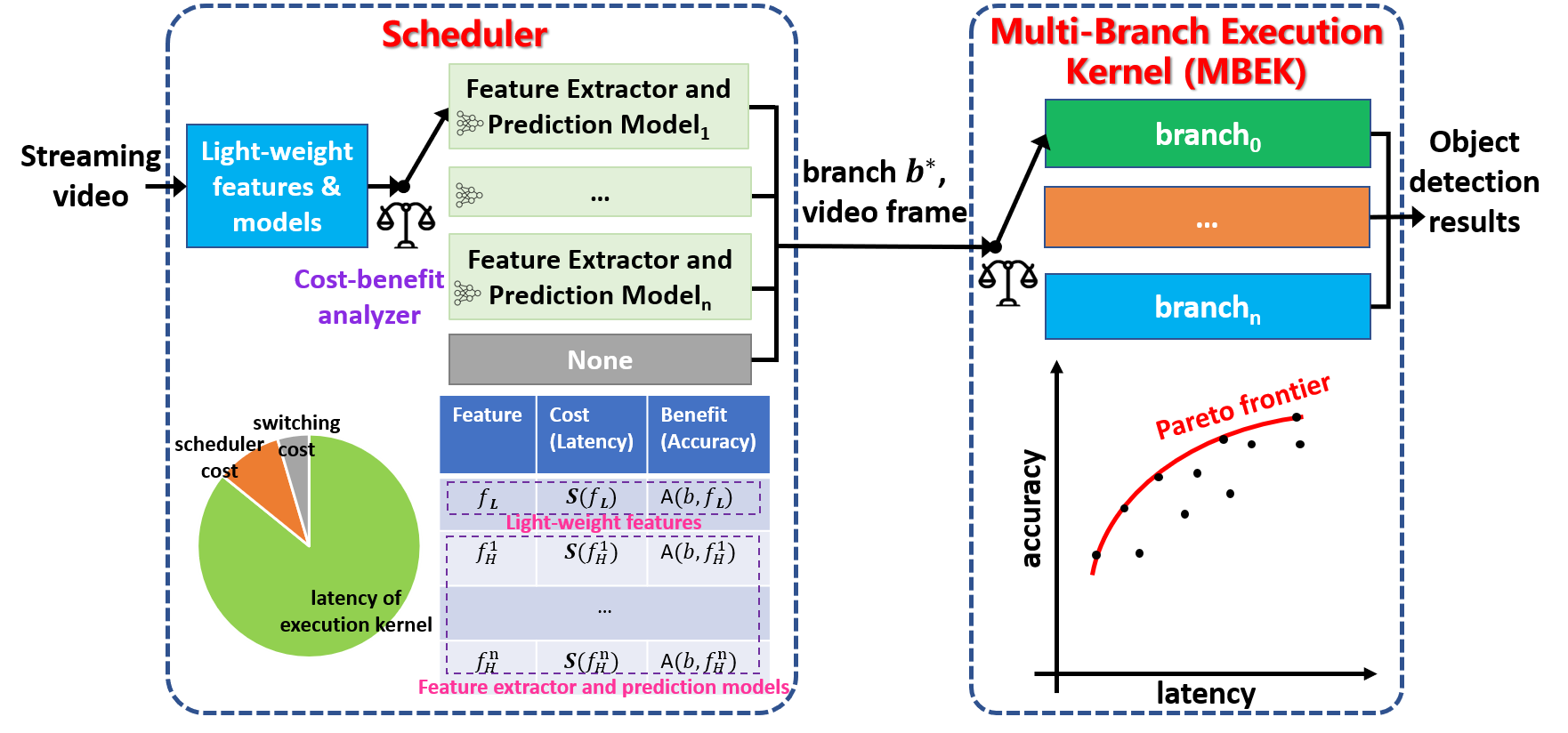
Abstract
An adaptive video object detection system selects different execution paths at runtime, based on video content and available resources, so as to maximize accuracy under a target latency objective (e.g., 30 frames per second). Such a system is well suited to mobile devices with limited computing resources, and often running multiple contending applications. Existing solutions suffer from two major drawbacks. First, collecting feature values to decide on an execution branch is expensive. Second, there is a switching overhead for transitioning between branches and this overhead depends on the transition pair. LiteReconfig, an efficient and adaptive video object detection framework, addresses these challenges. LiteReconfig features a cost-benefit analyzer to decide which features to use, and which execution branch to run, at inference time. Furthermore, LiteReconfig has a content-aware accuracy prediction model, to select an execution branch tailored for frames in a video stream. We demonstrate that LiteReconfig achieves significantly improved accuracy under a set of varying latency objectives than existing systems, while maintaining up to 50 fps on an NVIDIA AGX Xavier board. Our code, with DOI, is available at https://doi.org/10.5281/zenodo.6345733.
Cite
If you find this work useful in your own research, please consider citing:
@inproceedings{xu2022litereconfig,
title={{LiteReconfig}: Cost and Content Aware Reconfiguration of Video Object Detection Systems for Mobile GPUs},
author={Xu, Ran and Lee, Jayoung and Wang, Pengcheng and Bagchi, Saurabh and Li, Yin and Chaterji, Somali},
booktitle={Proceedings of the Seventeenth EuroSys Conference 2022 (EuroSys)},
pages={334--351},
year={2022}
}
Acknowledgement
This material is based in part upon work supported by the National Science Foundation under Grant Numbers CCF-1919197, CNS-2038986, CNS-2038566, and CNS-2146449 (NSF CAREER award). The authors thank the reviewers for their enthusiastic comments and the shepherd, Marc Shapiro, for his very diligent passes with us and his valuable insights that improved our paper.
For questions about paper, please contact Ran Xu at martin.xuran@gmail.com