Abstract
Advanced video analytic systems, including scene classification and object detection, have seen widespread success in various domains such as smart cities and autonomous systems. With an evolution of heterogeneous client devices, there is incentive to move these heavy video analytics workloads from the cloud to mobile devices for low latency and real-time processing and to preserve user privacy.
However, most video analytic systems are heavyweight and are trained offline with some pre-defined latency or accuracy requirements. This makes them unable to adapt at runtime in the face of three types of dynamism --- the input video characteristics change, the amount of compute resources available on the node changes due to co-located applications, and the user's latency-accuracy requirements change.
In this paper we introduce ApproxDet, an adaptive video object detection framework for mobile devices to meet accuracy-latency requirements in the face of changing content and resource contention scenarios.
To achieve this, we introduce a multi-branch object detection kernel, which incorporates a data-driven modeling approach on the performance metrics, and a latency SLA-driven scheduler to pick the best execution branch at runtime.
We evaluate ApproxDet on a large benchmark video dataset and compare quantitatively to AdaScale and YOLOv3. We find that ApproxDet is able to adapt to a wide variety of contention and content characteristics and outshines all baselines, e.g. it achieves 52% lower latency and 11.1% higher accuracy over YOLOv3. Our software is open-sourced at https://github.com/purdue-dcsl/ApproxDet.
Techniques
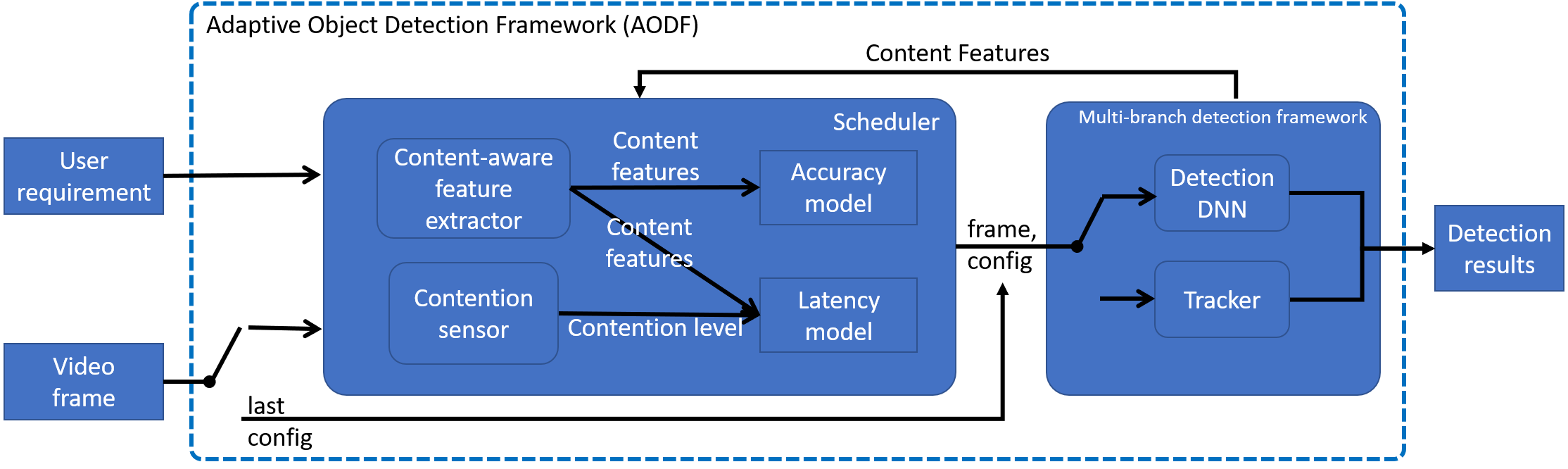
The above figure presents the overall workflow of our system ApproxDet. Our system consists of two modules --- a scheduler and a multi-branch object detection framework. The detection framework takes a video frame and a configuration as an input and produces the detection results while the scheduler decides which configuration the detection framework should use.
The detection framework includes two kernels: a detection kernel and a tracking kernel. This follows the common practice for video object detection that combines the heavy-weight detection and the light-weight tracker. At a high-level, the detection framework exposes five tuning knobs. With each tuning knob varying in a dynamic range, we construct a multi-dimensional configuration space and call the execution path of each configuration an approximation branch (AB).
The accuracy and the latency (execution time) are different for each AB and the values depend upon the video content characteristics (e.g. still versus fast-moving) and the compute resources available (e.g. lightly-loaded versus heavily-loaded mobile).
To efficiently select an AB at runtime according to the given (and possibly changing) user requirement, the scheduler estimates the current latency and accuracy of each branch.
The scheduler then selects the most accurate/fastest branch according to the specific user requirement.
We train an accuracy model and a latency model offline to support such estimation online.
To better predict such online performance metric, we build two lightweight online modules -- (1) a content-aware feature extractor, which extracts the height, width, tracks the object information of the last frame, and calculates the object movements of the past few frames, and (2) a contention sensor, which senses the current resource contention level.
Cite
If you find this work useful in your own research, please consider citing:
@inproceedings{xu2020approxdet,
title={{ApproxDet}: Content and contention-aware approximate object detection for mobiles},
author={Xu, Ran and Zhang, Chen-lin and Wang, Pengcheng and Lee, Jayoung and Mitra, Subrata and Chaterji, Somali and Li, Yin and Bagchi, Saurabh},
booktitle={Proceedings of the 18th ACM Conference on Embedded Networked Sensor Systems (SenSys)},
pages={449--462},
year={2020}
}
Funding Source
This material is based in part upon work supported by the National Science Foundation under Grant Number CNS-1527262, Army Research Lab under Contract number W911NF-20-2-0026, the Lilly Endowment (Wabash Heartland Innovation Network), and gift funding from Adobe Research. Yin Li acknowledges the support by the University of Wisconsin VCRGE with funding from WARF. We also thank the anonymous reviewers and our shepherd for their valuable comments to improve the quality of this paper.
For questions about paper, please contact Ran Xu at martin.xuran@gmail.com