Abstract
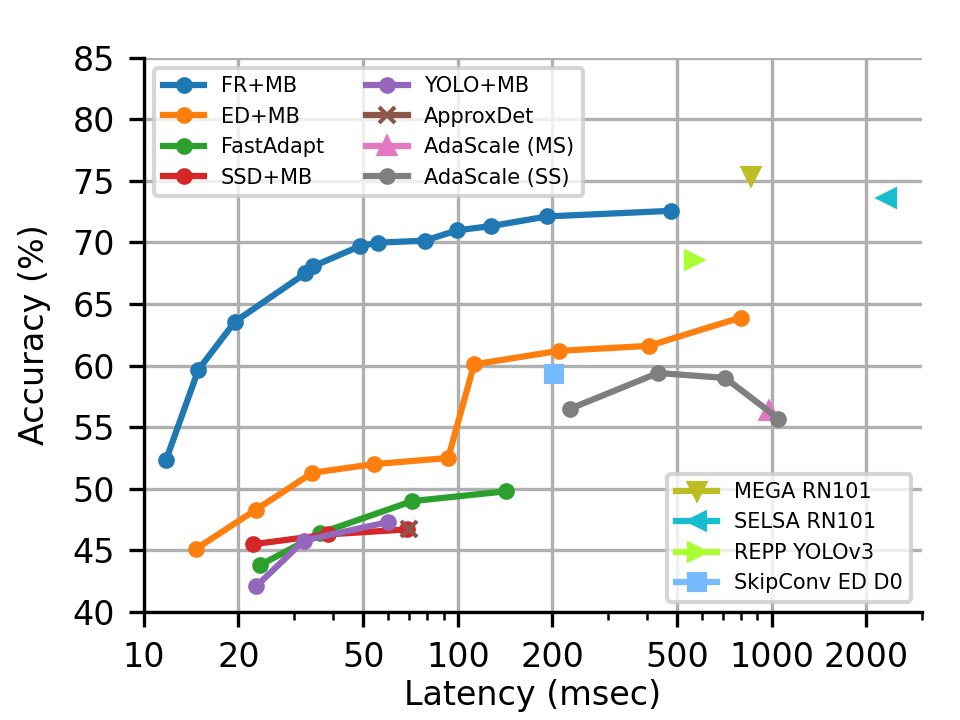
Several recent works seek to create lightweight deep networks for video object detection on mobiles. We observe that many existing detectors, previously deemed computationally costly for mobiles, intrinsically support adaptive inference, and offer a multi-branch object detection framework (MBODF). Here, an MBODF is referred to as a solution that has many execution branches and one can dynamically choose from among them at inference time to satisfy varying latency requirements (e.g. by varying resolution of an input frame). In this paper, we ask, and answer, the wide-ranging question across all MBODFs: How to expose the right set of execution branches and then how to schedule the optimal one at inference time? In addition, we uncover the importance of making a content-aware decision on which branch to run, as the optimal one is conditioned on the video content. Finally, we explore a content-aware scheduler, an Oracle one, and then a practical one, leveraging various lightweight feature extractors. Our evaluation shows that layered on Faster R-CNN-based MBODF, compared to 7 baselines, our SMARTADAPT achieves a higher Pareto optimal curve in the accuracy-vs-latency space for the ILSVRC VID dataset.
Cite
If you find this work useful in your own research, please consider citing:
@inproceedings{xu2022smartadapt,
title={{SmartAdapt}: Multi-branch Object Detection Framework for Videos on Mobiles},
author={Xu, Ran and Mu, Fangzhou and Lee, Jayoung and Mukherjee, Preeti and Chaterji, Somali and Bagchi, Saurabh and Li, Yin},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month={June},
pages={2528--2538},
year={2022}
}
Acknowledgement
This material is based in part upon work supported by the National Science Foundation under Grant Numbers CCF-1919197, CNS-2038986, CNS-2038566, and CNS-2146449 (NSF CAREER award), by the Amazon Web Service AI award, and by the Army Research Lab under contract numbers W911NF-20-2-0026 and W911NF-2020-221. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the sponsors.
For questions about paper, please contact Ran Xu at martin.xuran@gmail.com